
Just like the use of oil increased industrial transformation in the 20th century, data is fueling innovations in the 21st century. As leaders strive to transform their organizations, businesses leveraging data can help steer an enterprise in the right direction. Massive data (approximately 402 quintillion bytes of data are generated every day)1 comes from numerous sources, including finance, human resources, healthcare, retail, education, science, surveys, government, and IoT devices. This in-depth guide provides a detailed overview of the modern data architecture.
Five Characteristics of Modern Data
Today’s modern data differs from “traditional” data in five areas:
- Volume: The size of data sets is increasingly larger; units are now terabytes, petabytes, or exabytes.
- Velocity: The speed at which data is generated is now faster. Data can be received every month, day, hour, minute, and second.
- Variety: The sources of data are more numerous and varied than ever before, including various types of devices and systems, e.g., phones, vehicles, point-of-sale systems, social media, IoT devices, homegrown apps, etc. They can be structured data or unstructured data, like pictures or videos.
- Veracity: This refers to the quality and reliability of data. It’s important to maintain quality output to help ensure data integrity.
- Value: With data more diverse and detailed than ever before, businesses can unlock the full potential of their data to help enhance decision making, improve customer satisfaction, improve operational efficiency, and drive revenue growth.
Handling modern data requires a robust extract, transform, and load (ETL) data integration process. ETL consists of:
- Extracting data from various sources
- Transforming the data, i.e., cleansing data for quality and consistency integration to provide a unified view
- Data normalization
- Aggregation (providing insight by summarizing)
- Enrichment (adding additional information to enhance the data)
- Loading the data into purposely designed databases, etc.
Then, data from multiple sources can be ingested, stored, updated, analyzed, visualized, and governed properly.
The foundational goal for data ETL is for advanced analytics, which our analytics team at Forvis Mazars can provide, to leverage tools and technology to benefit your business through data-driven decisions.
How can organizations begin to answer myriad complicated questions within all sorts of complex environments? Sophisticated, disciplined, and modern data architecture is the right answer.
The Evolution of Data Architecture
Data architecture has evolved over the years. The computing history has also grown from single PC computing to network-based, and from web-based, grid computing to cloud-based.
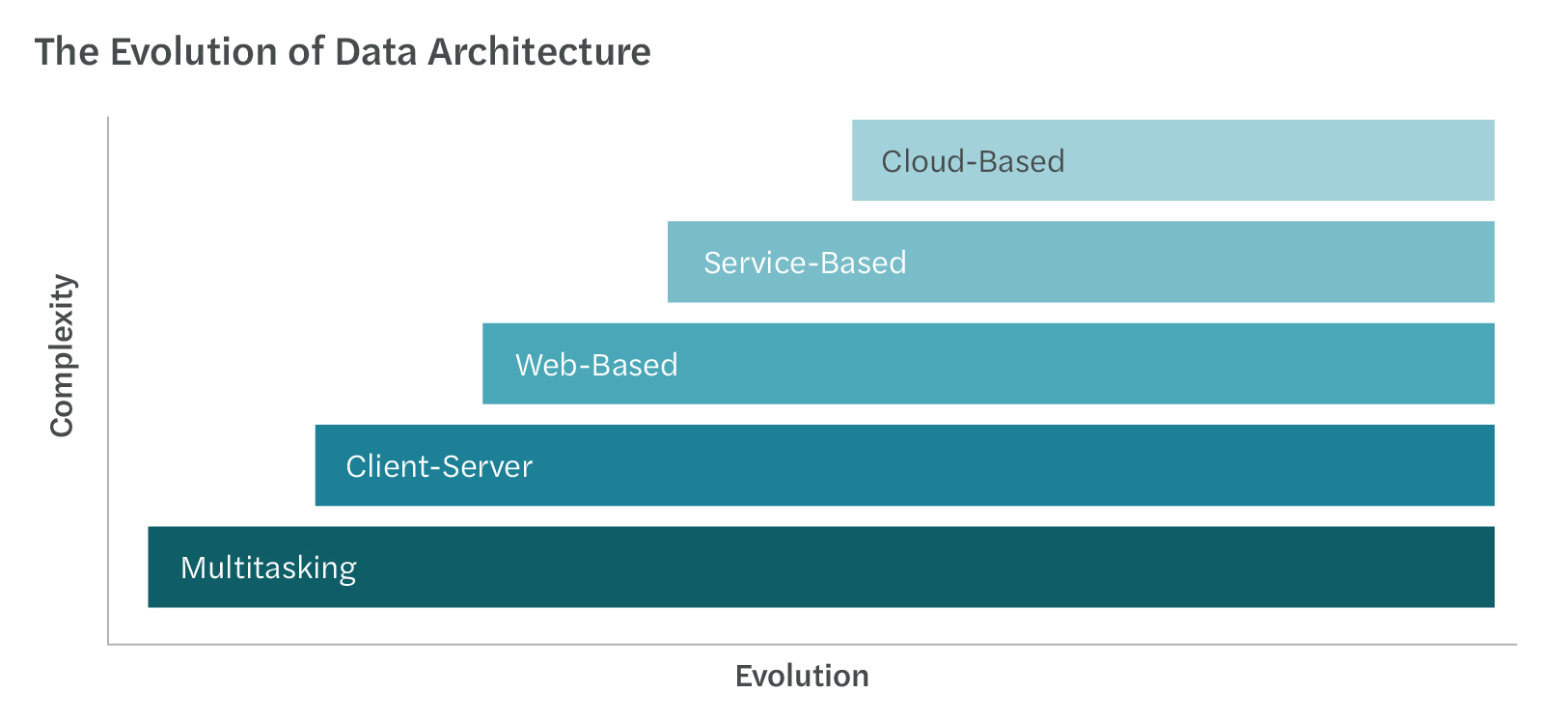
Organizations still reliant upon on-premises infrastructure are often constrained by rigid scalability, fragmented systems, and outdated tooling. Transitioning to cloud-based storage, compute, and ETL can provide a wide range of benefits, especially within the cloud ecosystem.
By adopting cloud-native services, businesses can seamlessly integrate with their customer relationship management (CRM) and enterprise resource planning (ERP) systems, e.g., Dynamics 365, visualization and dashboarding tools, e.g., Tableau, Power BI, Looker Studio, Qlik, etc., and perform their end-to-end ETL operations, e.g., Microsoft Fabric, Databricks, etc. For instance, storing data in a data lake or SQL database allows real-time access from CRM/ERP applications, so customer-facing teams can work with accurate and up-to-date insights. Cloud visualization tools natively connect with cloud-based services, allowing automated report refreshes and data-driven dashboards without complex pipelines or data duplication.
Cloud platforms also offer elastic scalability, automated backups, better disaster recovery, and the ability to innovate faster using artificial intelligence (AI) and machine learning (ML) tools, e.g., Amazon SageMaker, Azure Machine Learning, OpenAI integrations, Azure AI Foundry, etc.
Understanding Modern Data Storage Models
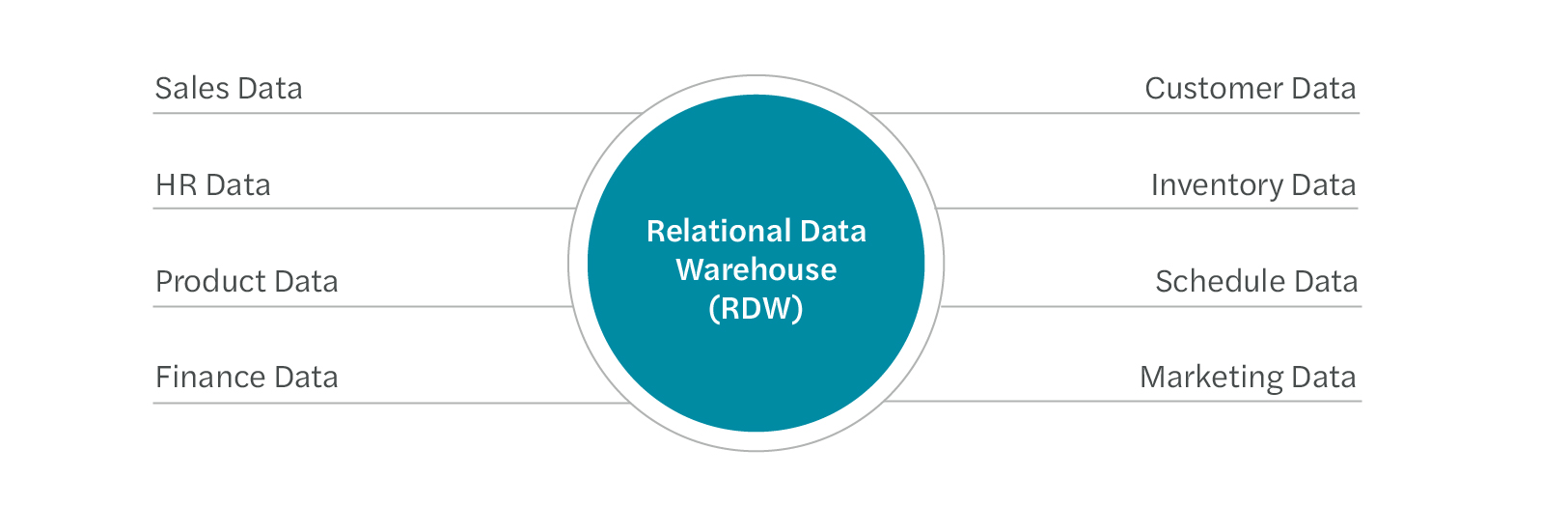
Data architecture in the early stages mostly relied on data warehouses, which centralize and normalize data into structured fact and dimension tables. Star schema was and is still prevalent in various databases within the data warehouses. The schema-on-write repositories design, where data is pre-structured and transformed before being stored, keeps high-performance data batch loading, processing, and fast query in mind, and the ultimate goal is for business intelligence (reporting and analysis).
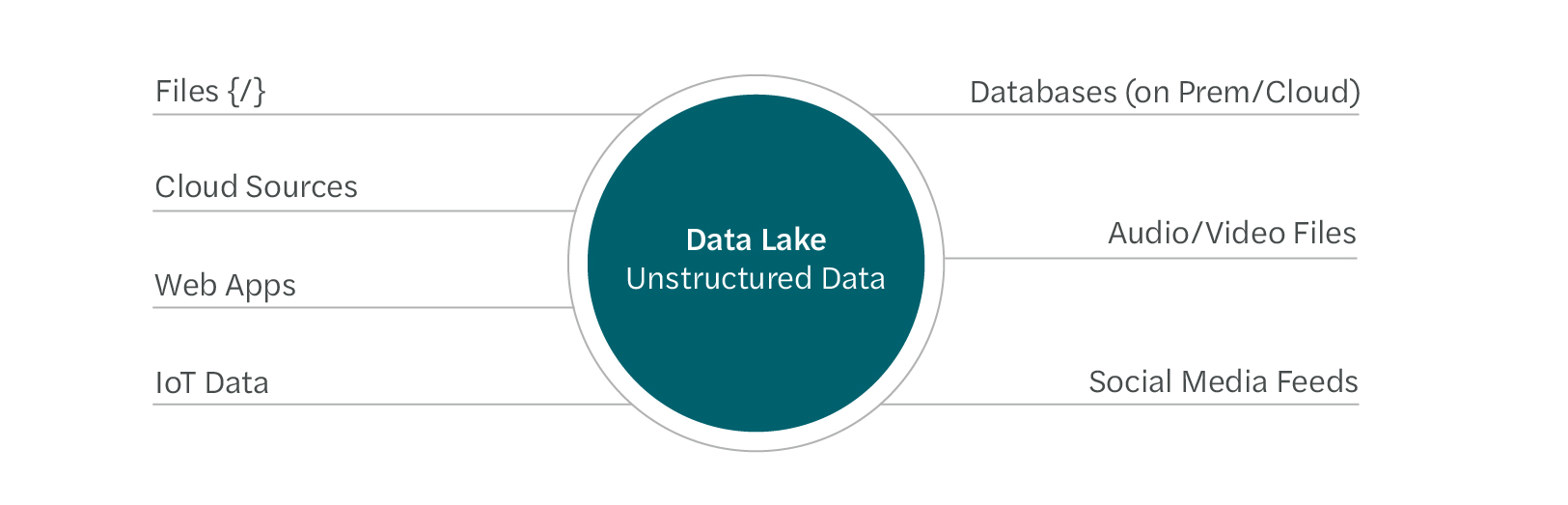
In the early 2000s, with “volume” growth and “variety” of data types, it became clear that traditional data warehouses for structured data were not enough. Data lakes emerged, and these schema-on-read repositories store structured, raw, semistructured, and unstructured data at scale. Netflix, for example, uses data lakes to collect and process big data about customer behavior to improve its recommendation algorithms. Data lakes are excellent for advanced analytics but may require specialized software for analysis.
Recently, the data lakehouse emerged (data lake + data warehouse), combining the best features of both architectures and providing a single platform for both structured and unstructured data. For example, retail businesses use data lakehouses to manage and analyze customers’ transactions and product inventory. They can leverage a “medallion architecture” to store raw data, e.g., point-of-sale system data, etc., in a bronze layer, identify and remove duplicate data in a silver layer, and then aggregate data to generate insights about marketing forecasting in a gold layer. A data lakehouse uses open file formats such as Parquet and JSON files to enable structured analytics on top of a lake. It supports big data analytics.
A data mart is a curated subset of a data warehouse that is subject-oriented, focusing on a specific business function or a particular department. The smaller size of data marts allows for faster data retrieval and analysis and is optimized for performance. There are three types of data marts: dependent, independent, and hybrid. A dependent data mart is created from a central data warehouse. An independent data mart is created from a standalone source, which is entirely different from the data warehouse. A hybrid data mart is a combination of both.
Pros & Cons of Modern Data Storage Models
Data Warehouse
Pros:
- Optimized for structured data and fast SQL queries
- Ideal for reporting and dashboarding tools like Power BI
- Mature ecosystem and strong governance support
Cons:
- Less suited for unstructured or semistructured data
- Expensive for storing large volumes of raw data
- Schema changes can be cumbersome and typically lack scalability
Data Lake
Pros:
- Handles vast volumes of structured and unstructured raw data
- Cost-effective storage
- Most data lake implementations enable AI/ML functionalities not available in traditional data warehouses
Cons:
- Failure to optimize data storage can lead to poor performance
- Requires strong governance to avoid becoming a “data swamp”
- Complexity in managing schema and data quality
Data Lakehouse
Pros:
- Merges benefits of lakes and warehouses
- Open format, e.g., Delta, allows easy interoperability
- Atomicity, consistency, isolation, and durability (ACID) transactions bring reliability to big data
Cons:
- Still a newer architecture with evolving standards
- Requires technical sophistication to manage effectively
- Integration with some legacy BI tools may need customization
Data Marts
Pros:
- Targeted, fast access for specific teams or functions
- Easier to maintain than a full data warehouse
- Promotes self-service analytics
Cons:
- Risk of data silos and duplication
- Can be hard to scale if not governed properly
- Requires alignment with enterprise data models
Common Architectures
| Data Warehouse | Data Lake | Data Lakehouse | Data Mart | |
|---|---|---|---|---|
| Data Structure | Structured | Unstructured | Both structured and unstructured | Both structured and unstructured |
| Schema Changes | Cumbersome | Difficult to manage | Complex | Simpler |
| SQL Queries | Optimized | Poor performance for traditional BI queries | Optimized | Optimized |
| Reporting Tool | Ideal | Needs configuration | Needs configuration | Ideal |
| Ecosystem Maturity | Mature | Mature | Mature | Mature |
| Data Sciences | Ideal for relational data | Flexible | Very flexible | Ideal for targeted data science projects |
| Cost | Expensive | Effective | Expensive | Effective |
How Forvis Mazars Can Help
A well-thought-out data architecture strategy can lay the foundation for leveraging data as a strategic asset. Once the data is mined and refined, your organization can maintain high-quality, accessible data, equipping you with enhanced decision-making capabilities. Leaders can rely on relevant data to help drive organizational growth, leading to operational efficiency and significant cost savings. Not sure where to begin? Contact our analytics team at Forvis Mazars for a consultation!
- 1“Big data statistics: How much data is there in the world?”, rivery.io, May 28,2025.